October 5, 2017
The big data processing started by focusing on the batch processing. Distributed data storage and querying tools like MapReduce, Hive, and Pig were all designed to process data in batches rather than continuously. Recently enterprises have discovered the power of analyzing and processing data and events as they happen instead of batches. Most traditional messaging systems, such as RabbitMq, neither scale up to handle big data in realtime nor use friendly with big data ecosystem. But, it is lucky that we have group of engineers at LinkedIn built and open-sourced distributed messaging framework that meets the demands of big data by scaling on commodity hardware, called Kafka.
What is Kafka?
Apache Kafka is messaging system built to scale for big data. Similar to Apache ActiveMQ or RabbitMq, Kafka enables applications built on different platforms to communicate via asynchronous message passing. But Kafka differs from these more traditional messaging systems in key ways:
- It’s designed to scale horizontally, by adding more commodity servers.
- It provides much higher throughput for both producer and consumer processes.
- It can be used to support both batch and real-time use cases.
- It doesn’t support JMS, Java’s message-oriented middleware API.
Kafka’s Architecture
There are some basic terminology used in Kafka architecture:
- A producer is process that can publish a message to a topic.
- A consumer is a process that can subscribe to one or more topics and consume messages published to topics.
- A topic category is the name of the feed to which messages are published.
- A broker is a process running on single machine.
- A cluster is a group of brokers working together.
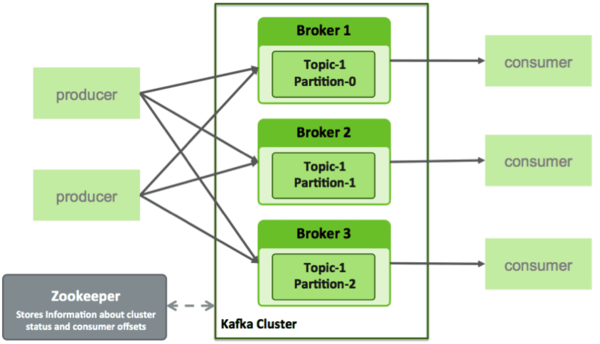
From above Kafka’s architecture, we can see it has a very simple design, which can result in better performance and throughput. Every topic in Kafka is like a simple log file. When a producer publishes a message, the Kafka server appends it to the end of the log file for its given topic. The server also assigns an offset, which is a number used to permanently identify each message. As the number of messages grows, the value of each offset increases; for example if the producer publishes three messages the first one might get an offset of 1, the second an offset of 2, and the third an offset of 3.
When the Kafka consumer first starts, it will send a pull request to the server, asking to retrieve any messages for a particular topic with an offset value higher than 0. The server will check the log file for that topic and return the three new messages. The consumer will process the messages, then send a request for messages with an offset higher than 3, and so on.
In Kafka, the client is responsible for remembering the offset count and retrieving messages.The Kafka server doesn’t track or manage message consumption. By default, a Kafka server will keep a message for seven days. A background thread in the server checks and deletes messages that are seven days or older. A consumer can access messages as long as they are on the server. It can read a message multiple times, and even read messages in reverse order of receipt. But if the consumer fails to retrieve the message before the seven days are up, it will miss that message.
Why Kafka so Quick
Kafka is fast for a number of reasons. Below are few aspects for your reference.
- Zero Copy: It calls the OS kernal direct rather than at the application layer to move data fast. Here is more explanation from wikipedia.
- Batch Data in Chunks - Kafka is all about batching the data into chunks. This minimises cross machine latency with all the buffering/copying that accompanies this.
- Avoids Random Disk Access - as Kafka is an immutable commit log it does not need to rewind the disk and do many random I/O operations and can just access the disk in a sequential manner. This enables it to get similar speeds from a physical disk compared with memory.
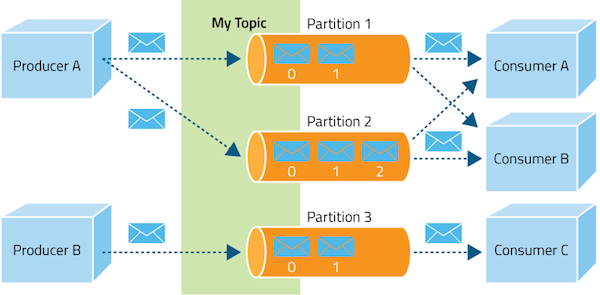
- Can Scale Horizontally - The ability to have thousands of partitions for a single topic spread among thousands of machines means Kafka can handle huge loads.
Future
At earlier of this year, Kafka has announced two important features brought by Confluent, which is the company started by that group of enginners in LinkedIn. One is Kafka Connect and the other is Kafka Stream. These two new “killing” features will be a big impact in the big data ecosystem. I’ll talk about them for more details in later posts.