Leading Cloud Tech. Stack Comparison
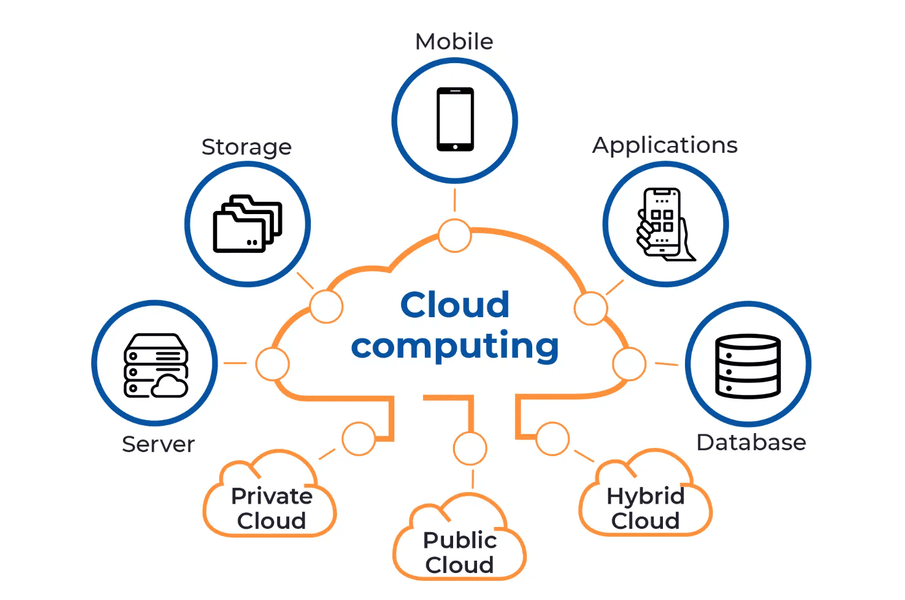
Introduction In today’s digital era, businesses are increasingly adopting cloud computing to scale their operations, enhance flexibility, and reduce costs. Among the major cloud service providers, Amazon Web Services (AWS), Microsoft Azure, Google Cloud, and Oracle Cloud have emerged as dominant players in the market. Each offers a comprehensive cloud technology stack tailored to meet different business needs. In this blog, we’ll conduct a thorough comparison of these leading cloud technology stacks to help you make an informed decision when choosing the best-fit cloud provider for your organization.




