June 17, 2018
Overview
NoSQL (NoSQL = Not Only SQL) means “not just SQL”. Modern computing systems generate a huge amount of data every day on the network. A large part of these data are handled by relational database management systems (RDBMSs). Its matured relational theory foundation makes data modeling and application programming easier. However, with the wave of informationization and the rise of the Internet, traditional RDBMSs have started to experience problems in some paticular domain.
First of all, the database storage capacity requirements are getting higher and higher. For instead, we have to use clusters to meet the demand of storage increasing. However, most RDBMS generally does not support fully distributed clusters especially on special operations such as join and union. Second, in today’s big data area, many of the data are “frequently read rather than frequently modified”, but RDBMS treats all operations equally. This brings oppotunities for performance optimization. In addition, the uncertainties in the Internet era cause the storage mode of the database to change frequently. The non-free and local storage mode increases the complexity of operation and maintenance and the difficulty of expansion.
NoSQL is a brand-new and revolutionary database movement. It has been proposed in the early days that the trend has been rising since 2009. This kind of database mainly has these characteristics: non-relational, distributed, open source, and horizontally scalable. The initial purpose was for large-scale web applications. NoSQL advocates advocate the use of non-relational data storage. The usual applications are: mode freedom, support for simple replication, simple APIs, eventual consistency (non-ACID), large-capacity data, and so on.
In below picture, it lists a commonly-used NoSQL database.

The Theory
ACID
ACID, refers to the database management system (DBMS) in the process of writing or updating data, in order to ensure the transaction (transaction) is correct and reliable, it must have four characteristics: Atomicity (atomicity, or indivisibility), Consistency, Isolation (also called independence), Durability.
A = Atomicity, all operations in a transaction are either completed or not completed and will not end in the middle. An error occurred during the execution of the transaction, and it was rolled back to the state before the transaction started, just as the transaction was never executed.
C = Consistency, the integrity of the database was not destroyed before and after the transaction began. This means that the written data must fully comply with all the preset rules, which include the accuracy of the data, the tandemness, and the follow-up database can spontaneously complete the scheduled work.
I = Isolation, the database allows multiple concurrent transactions to simultaneously read, write, and modify their data. Isolation prevents data from being inconsistent due to cross-execution when multiple transactions are executing concurrently. Transaction isolation is divided into different levels, including Read uncommitted, Read committed, Repeatable read, and Serializable.
D = Durability, after the transaction is completed, the data modification is permanent and will not be lost even if the system fails.
Relational databases strictly follow the ACID theory. However, when the database needs to meet the requirements of horizontal extension, high availability, and mode freedom, it is necessary to make a trade-off from ACID theories. As result, NoSQL databases theory based on CAP theory and BASE theory began to appear.
CAP
If we expect to implement a set of distributed transactions that strictly satisfy ACID, it is likely that there will be conflicts between system availability and strict consistency. There can never be a best of both worlds between usability and consistency. Since the basic requirement of NoSQL is to support distributed storage, strict consistency and availability need to be mutually discounted, thereby extending the CAP theory to define the problems encountered by distributed storage.
CAP theory tells us that a distributed system CANNOT meet three basic requirements of consistency (C: Consistency), availability (A: Availability), and partition fault tolerance (P: Partition tolerance), and it can only satisfy at most two of them as shown in the below picture. For a distributed system, partition fault tolerance is a basic requirement, otherwise it cannot be called a distributed system. So the architect needs to find a balance between C and A.
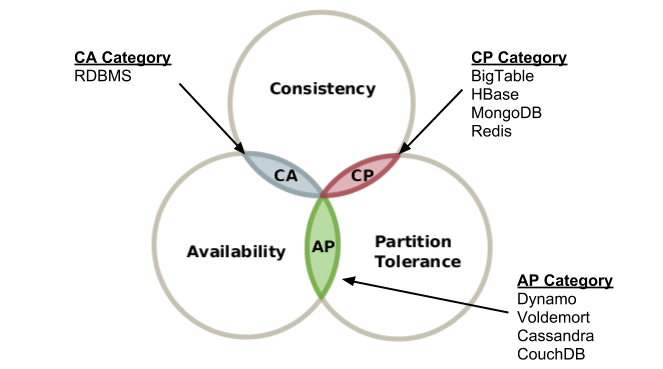
C = Consistency (completely different from AC of C), Consistency refers to “all nodes see the same data at the same time”, that is, when the update operation is successful and the return of the client is completed, the data of all nodes at the same time is exactly the same. For consistency, it can be divided into two different perspectives from the client and the server. From the perspective of the client, consistency mainly refers to the problem of how to obtain updated data when mple concurrent accesses are made. From the perspective of the server, it is how updates are distributed to the entire system to ensure that the data is ultimately consistent. Consistency is due to the problem of concurrent reading and writing. Therefore, when understanding the consistency problem, we must pay attention to the combination of concurrent reading and writing scenarios. From the perspective of the client, when multiple processes access concurrently, different strategies for how the updated data is obtained in different processes determine different consistency. For relational databases, the updated data can be seen by subsequent visits. This is strongly consistent. If we can tolerate some or all of the subsequent visits, it is weak consistency. If after a certain period of time it is required to access the updated data, it is ultimately consistent.
A = Availability, availability refers to “Reads and writes always succeed”, that is, the service is always available, and it is a normal response time. For an availability distributed system, each non-failed node must respond to every request. That is, any algorithm used by the system must eventually terminate. This is a strong definition when partition tolerance is required at the same time: even if it is a serious network error, each request must be completed. Good usability mainly refers to the fact that the system can serve users well and does not experience poor user experience due to user operation failure or access timeout. In the general case, availability has a lot to do with distributed data redundancy, load balancing, and so on.
P = Partition tolerance, Partition fault tolerance refers to “the system continues to operate (Architecture to operate to arbitrary message loss or failureof part of the system)”, that is, when a distributed system encounters a failure of a certain node or network partition, it can still provide services to meet the consistency and availability. Partition fault tolerance and scalability are closely related. In distributed applications, the system may not function properly due to some distributed reason. A good partition fault tolerance requirement can make an application a distributed system, but it seems to be a functioning whole. For example, if one or more machines in a distributed system are crashed, the remaining machines can still operate normally to meet the system requirements, or there are network exceptions between machines, and the distributed system is divided into several independent ones. Each part can also maintain the operation of the distributed system, so that it has good partition fault tolerance.
CA without P, If P (do not allow partitioning) is not required, C (strong consistency) and A (availability) are guaranteed. But in fact, the partition is not a problem that you want to think about, but it will always exist, so the CA system is more to allow the partitions to remain CA.
CP without A, If A (available) is not required, it means that each request needs to be strongly consistent between Servers, and P (partition) will cause the synchronization time to be infinitely extended, so the CP is also guaranteed. Many traditional database distributed transactions fall into this pattern.
AP without C, To be highly available and allow partitions, you must give up consistency. Once partitions occur, the nodes may lose contact. In order to be highly available, each node can only provide services with local data. This may cause inconsistency of global data. Many NoSQL now fall into this category.
CAP theory defines the fundamental issue of distributed storage, but it does not indicate how trade-offs between consistency and availability should be. Then the BASE theory emerged, giving a feasible solution to trade off A and C.
BASE
The BASE stands for Basically Available + Soft state + Eventually consistent, which is proposed by Dan Pritchett, an eBay architect. Base is the result of trade-offs between consistency A and availability C in the CAP, from the author’s own summary of practice on large-scale distributed systems. The core idea is that strong consistency cannot be achieved, but each application can use its own characteristics to achieve eventual consistency.
BA = Basically Available, This refers to the fact that when a distributed system fails, it is allowed to lose some of its availability, that is, to ensure that the core functions or the most important functions are currently available. For users, the availability of the features they are most concerned about or the most commonly used functions will be guaranteed, but other features will be weakened.
S = Soft State, Allowing system data to exist in an intermediate state does not affect the overall availability of the system, that is, it allows the system to have time delays in synchronizing data between different nodes’ data copies.
E = Eventually Consistent - Final Consistency, It is required that the system data copy be eventually consistent without the need to guarantee the consistency of the data copy in real time. Final consistency is a special case of weak consistency. There are 5 variants of the final consistency:
The Algorithm
Paxos
The problem solved by the Paxos algorithm is how a distributed system agrees on a certain value (resolution). A typical scenario is that in a distributed database system, if each node has the same initial state and each node performs the same sequence of operations, then they can finally get a consistent state. To ensure that each node executes the same sequence of commands, a “consistency algorithm” needs to be executed on each instruction to ensure that the instructions seen by each node are consistent. A universal consensus algorithm can be applied in many scenarios and is an important issue in distributed computing. Therefore, research on consensus algorithms has not stopped since the 1980s. There are two models of node communication: Shared memory and Messages passing. The Paxos algorithm is a consensus algorithm based on the messaging model.
It is not only in distributed systems that the Paxos algorithm can be used where multiple processes need to reach a certain consensus. Consensus algorithms can be implemented either through shared memory (locking required) or message passing, and the Paxos algorithm uses the latter. The Paxos algorithm is applicable to several situations: data consistency among multiple processes/threads in a single machine; multiple clients concurrently reading and writing data in a distributed file system or distributed database; multiple copies of distributed storage responding to read and write requests consistency.
Partitioning
All the original data is in a database, network IO and file IO are concentrated in a database, so CPU, memory, file IO, network IO may become the system bottleneck. The partition scheme is to put the data of a certain table or several related tables on a separate database, so that the CPU, memory, file IO, and network IO can be decomposed into multiple machines, thereby improving system processing. ability.
Replication
There are two modes of partitioning, one is the master-slave mode, which is used for read-write separation; the other is the replication mode, that is, the data in one table is decomposed into multiple tables. A partition can only be one of these modes.
Consistent Hashing
Consistent hashing algorithms are commonly used in distributed systems. For example, a distributed storage system stores data on a specific node. If an ordinary hash method is used, the data is mapped to a specific node, such as key%N, key is the key of the data, and N is a node of the machine. Number, if there is a machine that joins or exits the cluster, all data mappings will be invalid. If it is persistent storage, data migration will be done. If it is a distributed cache, other caches will be invalid.
The consistent hash basically solves the most critical problem in the P2P environment—how to distribute storage and routing in a dynamic network topology. Each node only needs to maintain a small amount of neighboring node information, and only a small number of related nodes participate in the maintenance of the topology when the node joins/exits the system. All of this makes consistent hashing the first practical DHT algorithm.
NoSQL Types
Key-Value Store Database
This kind of database will mainly use the hash table, in this table there is a specific key and a pointer to specific data. Key/value models for IT systems are simple and easy to deploy. However, if the DBA only queries or updates some of the values, the Key/value becomes inefficient.
- TokyoCabinet/Tyrant
- Redis
- Voldemort
- OracleBDB
Column storage database
This part of the database is usually used to deal with distributed storage of large amounts of data. The keys still exist, but they are characterized by multiple columns. These columns are arranged by the column family.
- Cassandra
- HBase
- Riak
- Document Database
Document database
The document database was inspired by the Lotus Notes office software, which is similar to the first key-value store. This type of data model is a versioned document, semi-structured documents are stored in a specific format, such as JSON. A document database can be thought of as an upgraded version of a key-value database that allows nesting of key values. And the document database is more efficient than the key database.
- CouchDB
- MongoDB
- SequoiaDB
- Graph database
Graphic database
The database of the graphic structure is different from other rows and columns and the rigid structure of the SQL database. It uses a flexible graphic model and can be extended to multiple servers. NoSQL databases do not have a standard query language (SQL), so database queries require a data model. Many NoSQL databases have RESTful data interfaces or query APIs.
- Neo4J
- InfoGrid
- InfiniteGraph
Pron and Cons
Prons
Easy to expand, there are many kinds of NoSQL databases, but there is a common feature that removes the relational nature of relational databases. There is no relationship between data, so it is very easy to expand. Also intangible, it brings with it the ability to expand at the architectural level.
Large amount of data, high performance, NoSQL databases have very high read/write performance, and they perform equally well under large data volumes. This is due to its unrelated nature and the simple structure of the database. Generally, MySQL uses Query Cache. Each time the table updates Cache, it is invalid. It is a large-scale Cache. For the frequently-interactive applications of web2.0, Cache performance is not high. The NoSQL Cache is a record-level, fine-grained Cache, so NoSQL performance at this level is much higher.
Flexible data model, NoSQL does not need to create fields for the data to be stored in advance and can store custom data formats at any time. In a relational database, adding or deleting fields is a very troublesome thing. If it is a very large amount of data, adding fields is a nightmare. This is particularly evident in the era of large data volume web 2.0.
High availability, NoSQL can easily implement a highly available architecture without compromising performance. Such as Cassandra, HBase model, can also achieve high availability by copying the model.
Cons
No standard, There is no standard defined for NoSQL databases, so no two NoSQL databases are equal.
There is no stored procedure, Most of the NoSQL databases do not have stored procedures.
Does not support SQL, Most of NoSQL does not provide support for SQL: If you do not support industry standards such as SQL, you will have a certain amount of learning and application migration costs for users.
The support features are not rich enough and the products are not mature enough, the functions provided by existing products are relatively limited, unlike MS SQL Server and Oracle, which can provide various additional functions such as BI and reports. Most of the products are still in the initial stage, and the improvement of relational databases for decades is not the same.