August 4, 2018
Kafka consumer is what we use quite often to read data from Kafka. Here, we use this article to explain some key concepts and topics regarding to consumer architecture in Kafka.
Consumer Groups
We can always group consumers into a consumer group by use case or function of the group. One consumer group might be responsible for delivering records to high-speed, in-memory microservices while another consumer group is streaming those same records to Hadoop. Consumer groups have names to identify them from other consumer groups.
A consumer group has a unique id. Each consumer group is a subscriber to one or more Kafka topics. Each consumer group maintains its offset per topic partition. If you need multiple subscribers, then you have multiple consumer groups. A record gets delivered to only one consumer in a consumer group.
Each consumer in a consumer group processes records and only one consumer in that group will get the same record. Consumers in a consumer group load balance record processing.
Load Balance
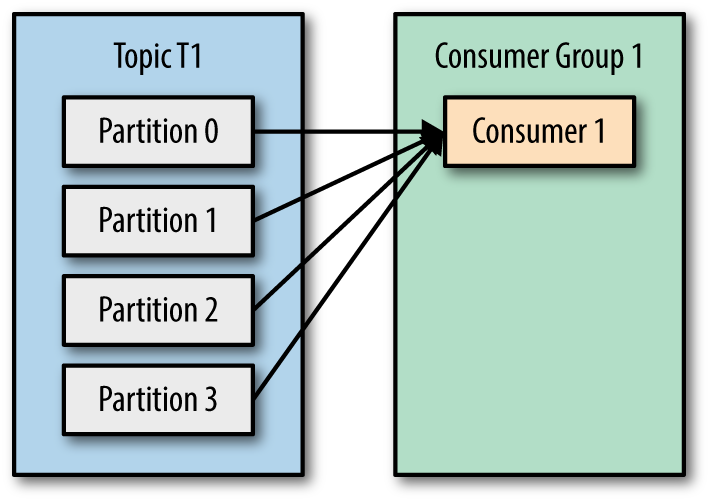
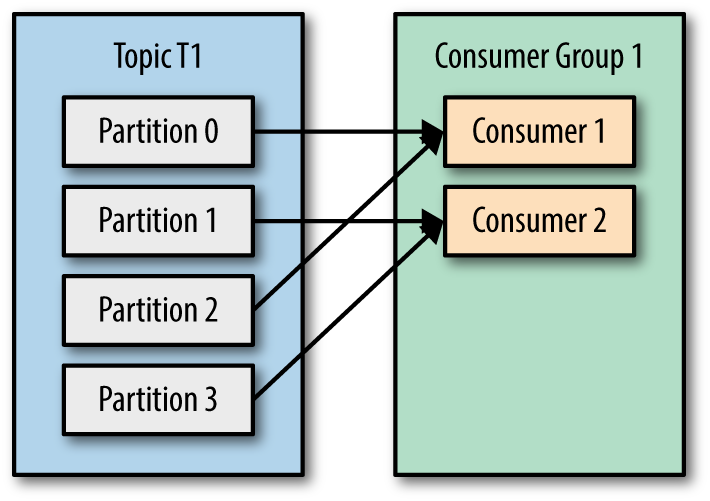
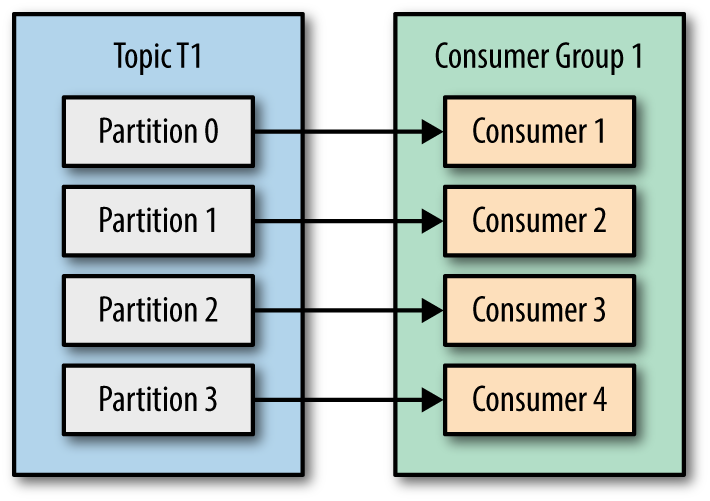
Kafka consumer consumption divides partitions over consumer instances within a consumer group. Each consumer in the consumer group is an exclusive consumer of a “fair share” of partitions. This is how Kafka does load balancing of consumers in a consumer group. Consumer membership within a consumer group is handled by the Kafka protocol dynamically. If new consumers join a consumer group, it gets a share of partitions. If a consumer dies, its partitions are split among the remaining live consumers in the consumer group. This is how Kafka does fail over of consumers in a consumer group. There are some pictures from Kafka definitive guide makes this more clearly.
| One Consumer group with four partitions | Four partitions split to two consumers in a group. |
|---|---|
 |
 |
| Four consumers in a group with one partition each | More consumers in a group than partitions means idle consumers. |
|---|---|
 |
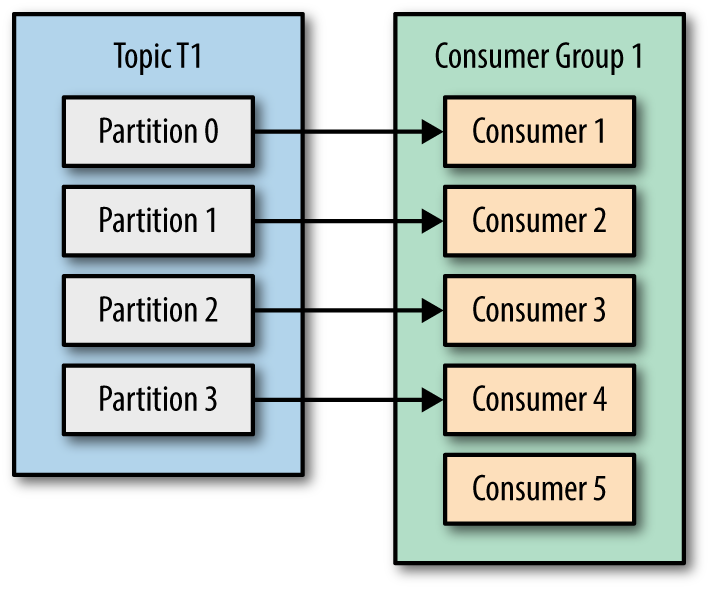 |
Only a single consumer from the same consumer group can access a single partition. If consumer group count exceeds the partition count, then the extra consumers remain idle. Kafka can use the idle consumers for failover. If there are more partitions than consumer group, then some consumers will read from more than one partition.
Failover
Consumers notify the Kafka broker when they have successfully processed a record, which advances the offset. * If a consumer fails before sending commit offset to Kafka broker, then a different consumer can continue from the last committed offset. * If a consumer fails after processing the record but before sending the commit to the broker, then some Kafka records could be reprocessed. In this scenario, Kafka implements the at least once behavior, and you should make sure the messages (record deliveries ) are idempotent.
Offset Management
Kafka stores offset data in a topic called __consumer_offset. These topics use log compaction, which means they only save the most recent value per key. When a consumer has processed data, it should commit offsets. If consumer process dies, it will be able to start up and start reading where it left off based on offset stored in __consumer_offset or as discussed another consumer in the consumer group can take over.
Consume Scope
What is the scope of records can be consumed by a Kafka consumer? Consumers can’t read un-replicated data. Kafka consumers can only consume messages beyond the High Watermark offset of the partition. Log end offset is offset of the last record written to log partition and where producers writes to next. High Watermark is the offset of the last record that was successfully replicated to all partition’s followers. Consumer only reads up to the “High Watermark”.
Multi-threaded
You can run more than one Consumer in a JVM process by using threads.
Consumer with many threads
If processing a record takes a while, a single Consumer can run multiple threads to process records, but it is harder to manage offset for each Thread/Task. If one consumer runs multiple threads, then two messages on the same partitions could be processed by two different threads which make it hard to guarantee record delivery order without complex thread coordination. This setup might be appropriate if processing a single task takes a long time, but try to avoid it.
Thread per consumer
If you need to run multiple consumers, then run each consumer in their own thread. This way Kafka can deliver record batches to the consumer and the consumer does not have to worry about the offset ordering. A thread per consumer makes it easier to manage offsets. It is also simpler to manage failover (each process runs X num of consumer threads) as you can allow Kafka to do the brunt of the work.
Code Examples
Below is a simple consumer example with Java client.
public class Consumer {
public static void main(String[] args) {
Properties properties = new Properties();
properties.put("bootstrap.servers", "localhost:9092");
properties.put("key.deserializer", "org.apache.kafka.common.serialization.StringDeserializer");
properties.put("value.deserializer", "org.apache.kafka.common.serialization.StringDeserializer");
properties.put("group.id", "test-group");
KafkaConsumer kafkaConsumer = new KafkaConsumer(properties);
List topics = new ArrayList();
topics.add("kafka-topic-consume");
kafkaConsumer.subscribe(topics);
try{
while (true){
ConsumerRecords records = kafkaConsumer.poll(10);
for (ConsumerRecord record: records){
System.out.println(
String.format(
"Topic - %s, Partition - %d, Value: %s", record.topic(), record.partition(), record.value()
));
}
}
}catch (Exception e){
System.out.println(e.getMessage());
}finally {
kafkaConsumer.close();
}
}
}